
Introduction
Large Language Models (LLMs) have proven remarkably effective at handling general-purpose queries, but they struggle when precision, domain-specificity, or continuously evolving knowledge are required. Out-of-the-box, their responses are often too shallow or prone to hallucination, which makes them unsuitable for production-grade information retrieval tasks.
Retrieval-Augmented Generation (RAG) was introduced as a solution to this limitation, bridging LLMs with external knowledge bases. Yet, most “naive” RAG implementations remain constrained: they typically rely on basic vector similarity search and flat document retrieval, lacking deeper semantic reasoning, graph-based relationships, or robust orchestration capabilities. As a result, these pipelines often fail to deliver the context-rich, reliable answers demanded by real-world applications in domains such as legal or healthcare.
This is where LightRAG comes into play. LightRAG enriches retrieval by leveraging structured knowledge representations and semantic graphs, enabling more accurate and context-aware responses.
However, LightRAG is a single-query tool, and does not support chat history or other components within workflows. N8N, in turn, provides a powerful workflow automation layer, making it possible to seamlessly integrate enhanced RAG pipelines into operational systems and complex data flows. This is achieved through AI agents, which can leverage LightRAG alongside other tools to deliver more tailored responses and actions.
In this post, I’ll walk through my experience combining LightRAG with N8N to move beyond naive RAG and build a more robust, production-ready approach to information retrieval.
How LightRAG works
First, a RAG system must process documents. Instead of retrieving isolated text chunks from them, like standard RAG solutions, LightRAG also constructs a knowledge graph where entities, concepts, and their relationships are explicitly represented. This allows the system to capture semantic connections that naive RAG pipelines typically miss.
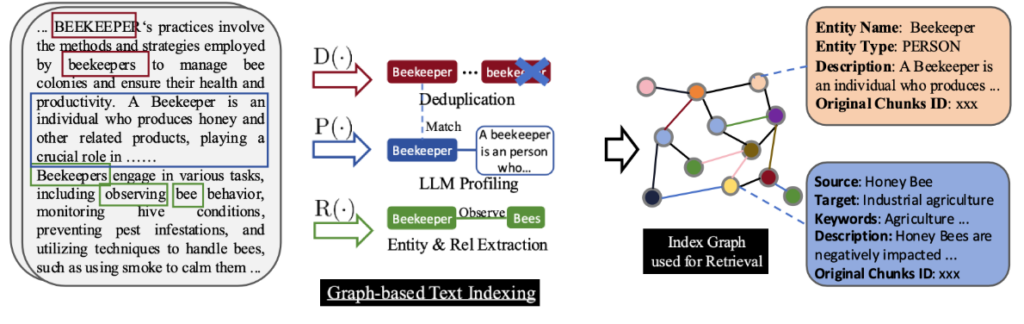
At retrieval time, when a query is received, it pulls the most similar passages like standard RAG solutions do, but LightRAG also performs a graph-based retrieval process to identify the most relevant nodes and relationships.
Finally, the retrieved graph substructure and the most relevant text chunks are fed into the LLM, which can leverage both the textual evidence and the relational context. The result is a response that is not only grounded in the source documents but also informed by semantic structure and contextual relevance, enabling higher-quality answers for complex, domain-specific use cases.
That’s awesome, now show me the code!
We will set up our workbench with Docker Compose, a tool for defining and running multi-container applications. Docker Compose uses a a docker-compose.yml file that specifies all the configuration required by the containers.
First, we define the PostgreSQL service—a database server with basic vector storage capabilities. The Docker Hub image shangor/postgres-for-rag is well-suited to our needs, as it comes with both the pgvector and Apache AGE extensions preinstalled. This image uses fixed defaults rag/rag/rag for the database name, user, and password, and cannot be configured via environment variables.
services:
postgres:
container_name: postgres
image: shangor/postgres-for-rag:v1.0
container_name: postgres
volumes:
- postgres_data:/var/lib/postgresql/16/main
ports:
- "5432:5432"
environment: {}
restart: unless-stopped
volumes:
postgres_data:Then, we add the LightRAG service:
services:
postgres:
...
lightrag:
container_name: lightrag
image: ghcr.io/hkuds/lightrag:latest
ports:
- "9621:9621"
volumes:
- lightrag_data:/app/data
env_file:
- .lightrag-env
restart: unless-stopped
volumes:
postgres_data:
lightrag_data:We will keep all the configuration in a separate .lightrag-env file. Since it is quite large, placing it directly in the docker-compose.yml would bloat the file. There are many environment variables available, but here I will only show the ones I have configured.
### Reranker Configuration
RERANK_BINDING=cohere
RERANK_MODEL=rerank-v3.5
RERANK_BINDING_HOST=https://api.cohere.com/v2/rerank
RERANK_BINDING_API_KEY=YOUR_API_KEY
### LLM Configuration
LLM_BINDING=openai
LLM_MODEL=gpt-4.1-mini
LLM_BINDING_HOST=https://api.openai.com/v1
LLM_BINDING_API_KEY=YOUR_API_KEY
### Embedding Configuration
EMBEDDING_BINDING=openai
EMBEDDING_MODEL=text-embedding-3-small
EMBEDDING_DIM=1536
EMBEDDING_BINDING_HOST=https://api.openai.com/v1
EMBEDDING_BINDING_API_KEY=YOUR_API_KEY
### Storage Configuration
LIGHTRAG_KV_STORAGE=PGKVStorage
LIGHTRAG_DOC_STATUS_STORAGE=PGDocStatusStorage
LIGHTRAG_GRAPH_STORAGE=PGGraphStorage
LIGHTRAG_VECTOR_STORAGE=PGVectorStorage
### PostgreSQL Configuration
POSTGRES_HOST=postgres
POSTGRES_PORT=5432
POSTGRES_USER=rag
POSTGRES_PASSWORD=rag
POSTGRES_DATABASE=rag
POSTGRES_MAX_CONNECTIONS=12For testing purposes, I’ve used OpenAI, which is inexpensive and easy to set up. If you have access to a capable GPU, you can also run an Ollama service as an alternative.
Using a reranker is crucial, as it greatly enhances the quality of responses provided by LightRAG. In my case, I chose Cohere, which offers a simple free plan, perfectly sufficient for our testing needs.
Finally, we must add the N8N service. With N8N, we will implement the AI agent that leverages LightRAG as one of its tools.
services:
postgres:
...
lightrag:
...
n8n:
image: n8nio/n8n:latest
ports:
- "5678:5678"
env_file:
- .n8n-env
volumes:
- n8n_data:/home/node/.n8n
depends_on:
- postgres
restart: unless-stopped
volumes:
postgres_data:
lightrag_data:
n8n_data:DB_TYPE=postgresdb
DB_POSTGRESDB_HOST=postgres
DB_POSTGRESDB_PORT=5432
DB_POSTGRESDB_DATABASE=rag
DB_POSTGRESDB_USER=rag
DB_POSTGRESDB_PASSWORD=rag
N8N_HOST=http://localhost
N8N_PORT=5678
N8N_PROTOCOL=http
N8N_COMMUNITY_PACKAGES_ALLOW_TOOL_USAGE=trueNow we can run docker compose up to deploy our stack. We will have LightRAG available at http://localhost:9621
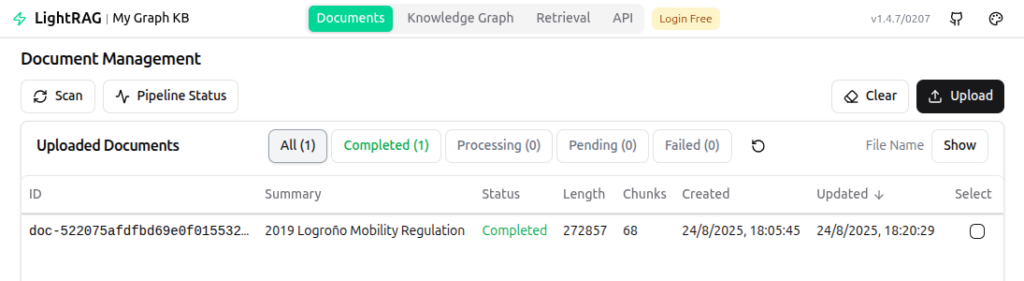
In the screen above, I’ve already uploaded a document of my city’s mobility regulation. It covers cycle lanes, pedestrian areas, traffic, and how they interact within the urban environment. After waiting for the processing to be done (~15 minutes for a 130 page document), we can check out the knowledge graph and even make queries.
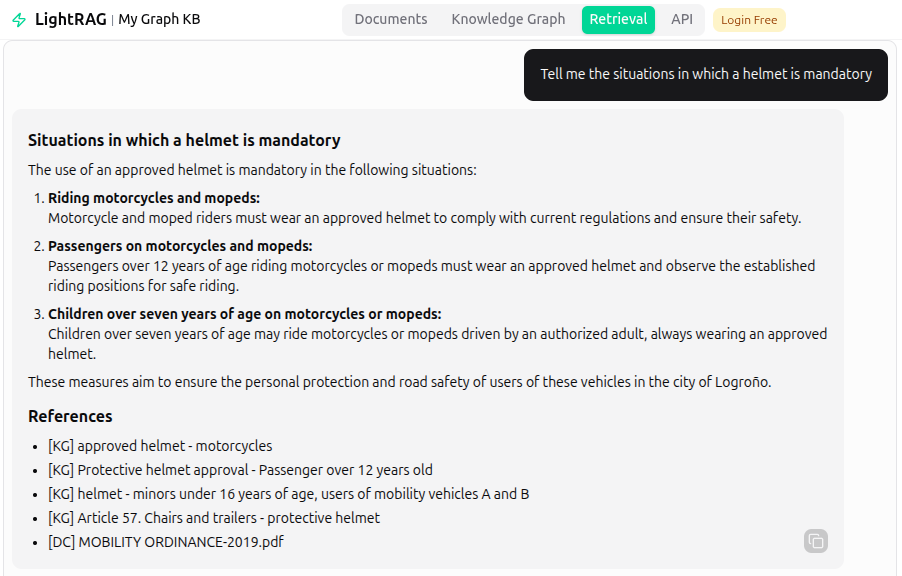
We obtained a fairly good response, along with the references used by the algorithm:
- [KG] – References in the Knowledge Graph: either single entities or relations between two entities.
- [DG] – Text chunks retrieved from a document.
We can also play with different parameters: Query mode (global, local, hybrid… etc.), response format, KG Top K, Chunk Top K, whether to enable or not reranking… refer to the LightRAG documentation for more info on these topics.
Introducing N8N
LightRAG can handle simple queries, but it lacks chat history, a system prompt (although it seems to have a “User Prompt” setting, it didn’t work for me), and other tools needed to properly manage a complete automation pipeline.
With N8N, we can implement the ideal orchestration mechanisms to fully unleash LightRAG’s search capabilities. We will set up a basic AI agent that includes a “LightRAG Tool”, which it can use to perform searches while generating more thoughtful responses that are also aligned with a custom system prompt.
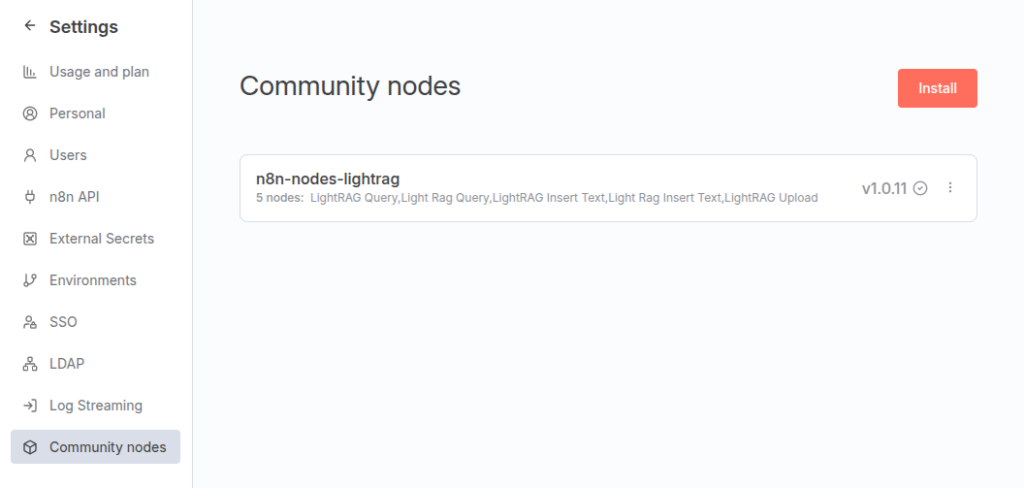
Installing the LightRAG Tool
There is not an official node for interacting with LightRAG. Fortunately, there is a contributed one: n8n-nodes-lightrag, that will allow us connecting an AI agent with our LightRAG instance.
Go to settings, in the bottom left corner, under the three points button:
In the next screen, go to “Community Nodes” and install it:
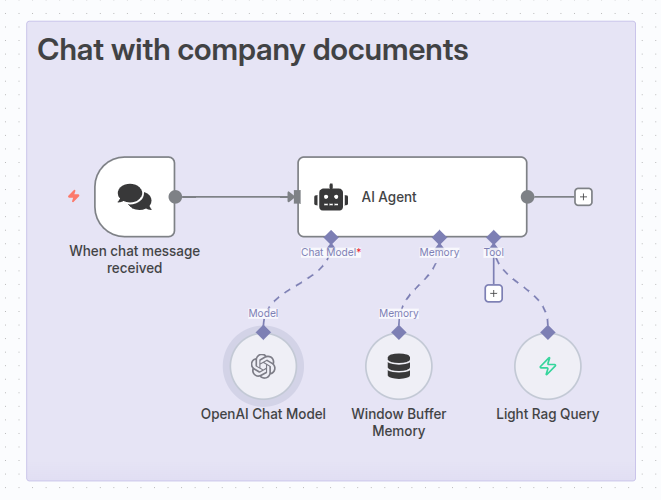
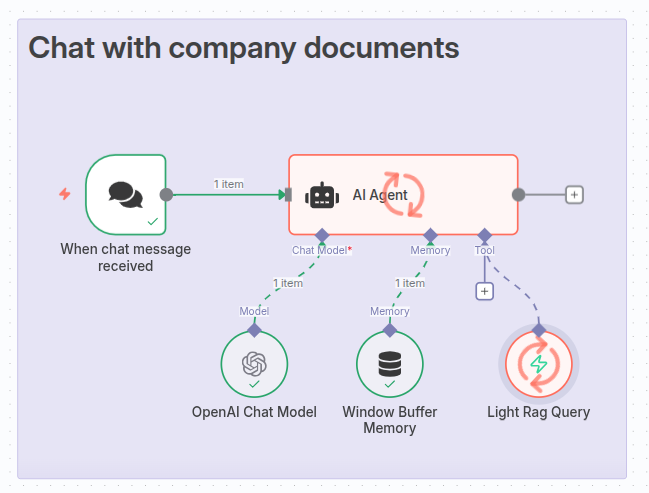
Creating our AI Agent
Now it’s finally time to create our AI Agent. We will use an OpenAI Model with gpt-4.1-mini configured, a simple memory node, and our LightRAG Tool
For our system prompt, we will use simple instructions:
You are an information assistant on Urban Mobility in Logroño, designed to answer user questions based on municipal regulations.
Retrieve relevant information and provide a concise, precise, and informative response to the user’s question. To do so, always use the "Light Rag Query" tool to fetch information from the company’s corpus, which is hosted on a LightRAG server. You should ask the tool any questions you deem necessary, including multiple queries if needed.
This tool will always return an answer along with the references used, for example:
------------------------------
Question:
Tell me in which cases wearing a helmet is required.
Answer:
Wearing a helmet is mandatory in several cases according to the regulations… etc.
References
[KG] certified helmet
[KG] certified helmet – motorcycles
[DC] MOBILITY-ORDINANCE-2019.pdf
------------------------------
A [KG] reference means it was obtained from the Knowledge Graph and can be either:
- [KG] entity: A single entity
- [KG] entity1 – entity2: A relationship between entity1 and entity2
A [DC] reference means it was obtained from text chunks in documents:
- [DC] document name
However, you should not provide the references used unless explicitly asked for them.
If the answer cannot be found using the "Light Rag Query" tool, respond with:
"I cannot find the answer in the available resources."We must also configure the LightRAG Tool. First, configure the URL where N8N can access the lightRAG server. As we have a Docker internal network, every container is seen by the others by its name, in our case “lightrag”.
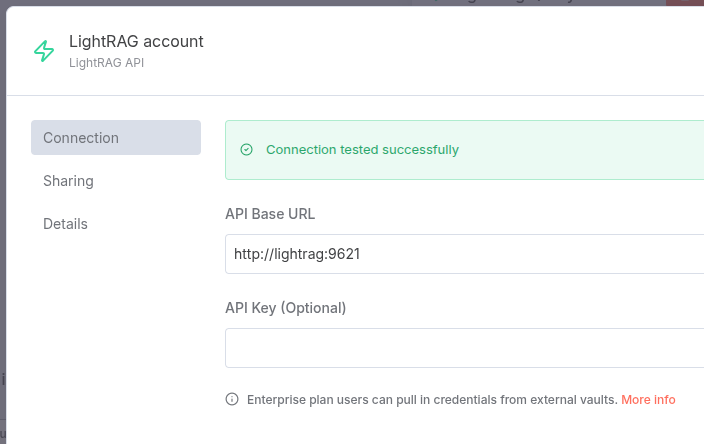
Then, configure the query to be provided by the model, the “mix” strategy and enable reranking:
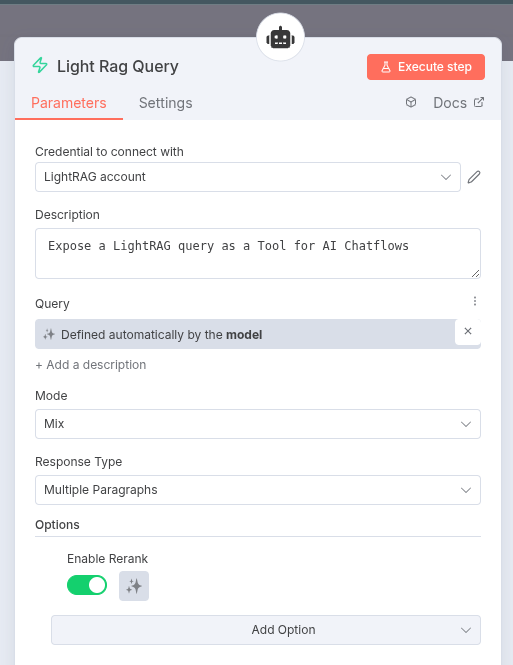
You can try out the different modes to observe their differences. For more details, refer to the LightRAG documentation.
Evaluating our agent
Finally, we can open a chat session with our agent and ask any question. For example:
Our AI Agent will start processing the request:
We inmediately receive a response, and we can check out the execution process, as it is logged.
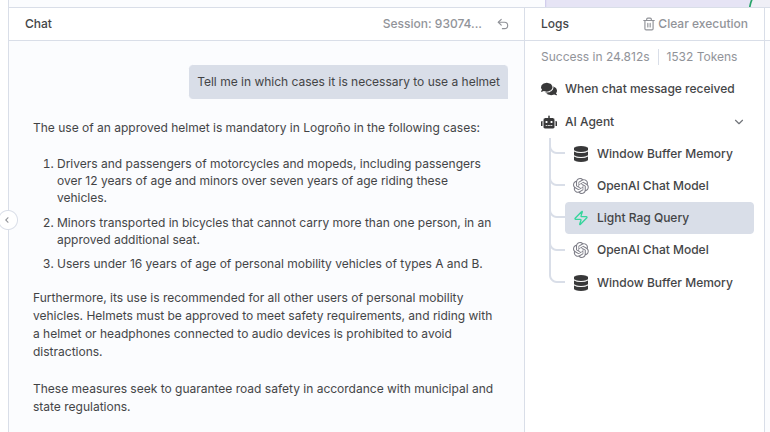
This is the query that our agent sent to LightRAG, and its response:
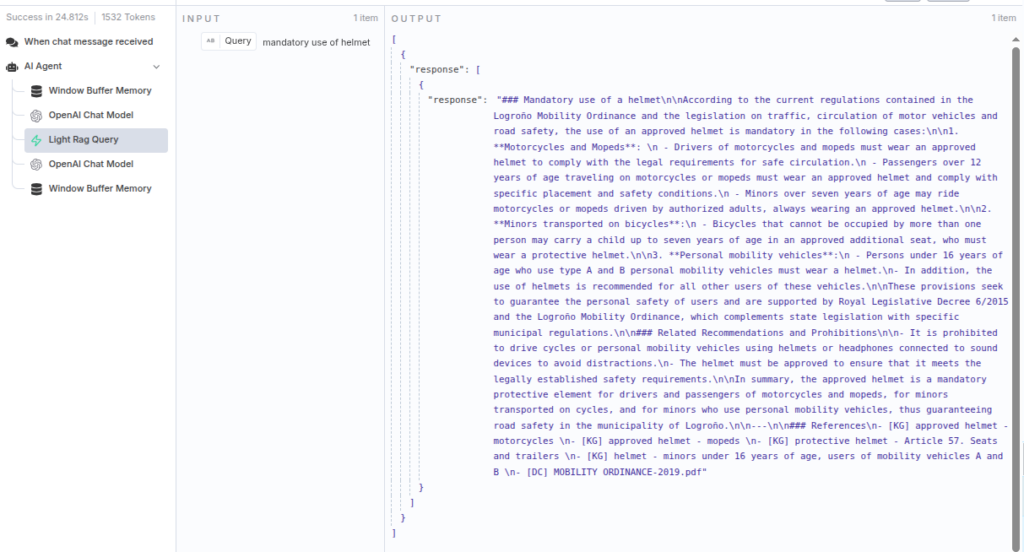
We can see that the response is quite similar to the one provided by LightRAG, but this was a relatively simple question. We could instruct our agent to query LightRAG more effectively, respond in a more informal tone, consult other information sources, or even perform actions.
Let’s try a more complicated question:
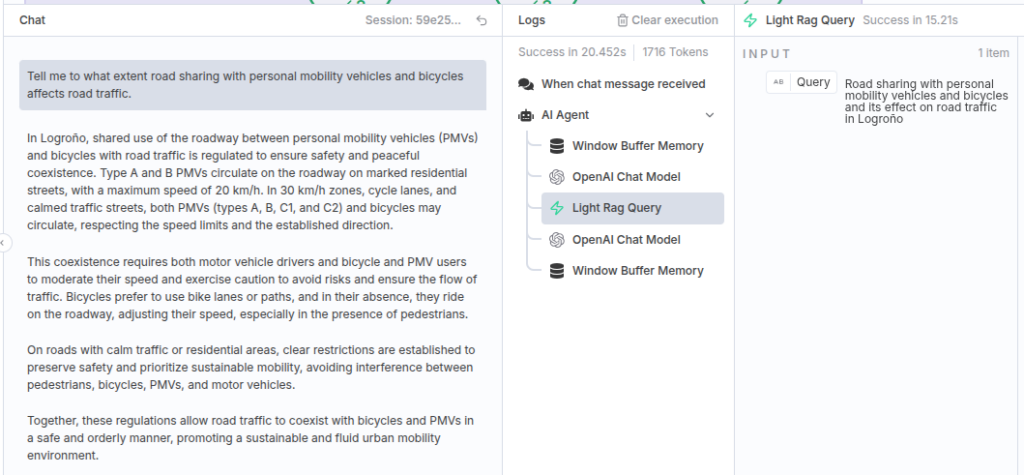

We can observe how the agent synthesizes the information. It adds another layer of abstraction, allowing it to emphasize certain aspects of the information provided by LightRAG.
However, this example still doesn’t add much beyond simple LightRAG queries. But keep in mind that, with N8N, the possibilities are vast: for instance, we could equip the agent with a weather tool that checks today’s conditions and advises the user on any precautions they should take.
Conclusion
LightRAG represents a significant advancement in the field of Retrieval-Augmented Generation. It outperforms traditional or “naive” RAG solutions by combining efficient knowledge retrieval with contextual reasoning, all while maintaining a moderate token cost. This makes it a powerful tool for building intelligent, scalable, and cost-effective information systems.
